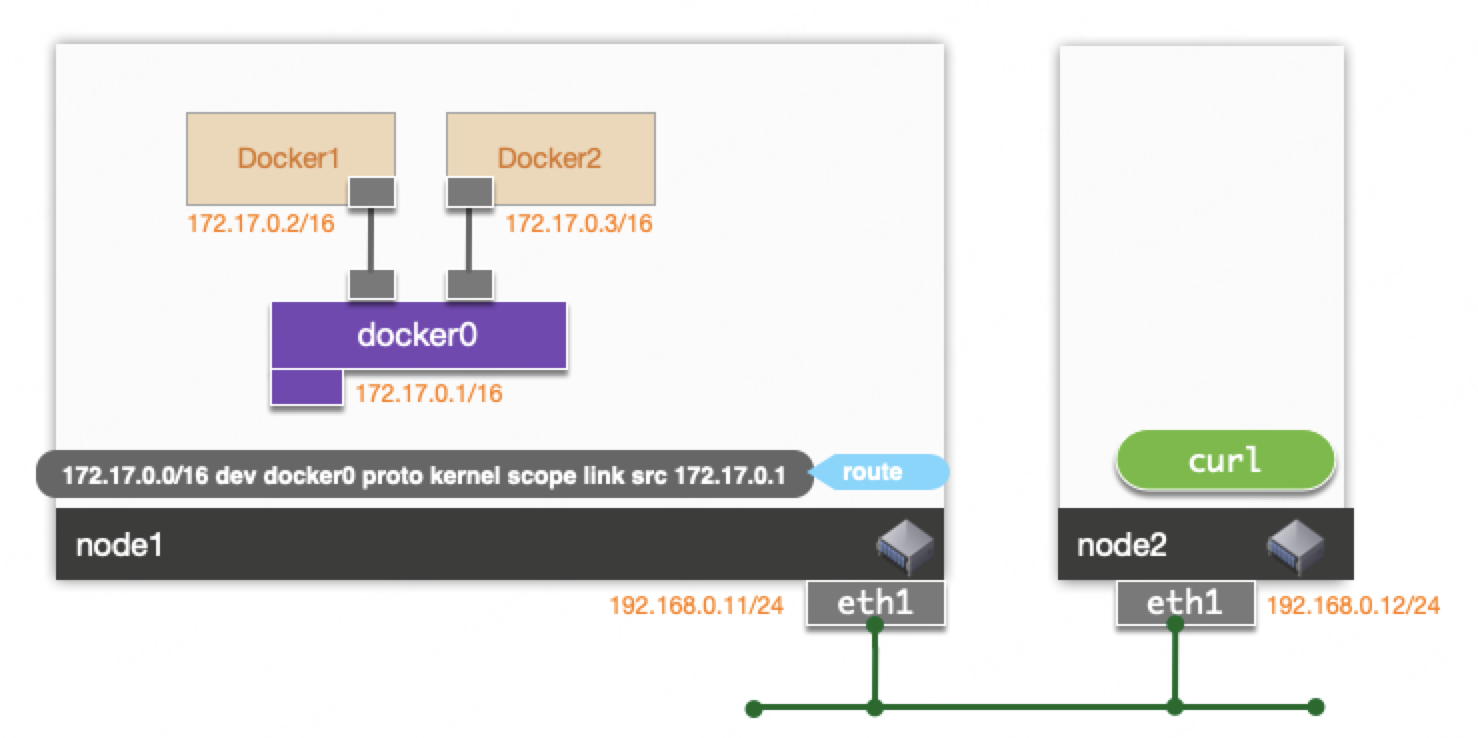
Docker默认的网络模式是bridge模式, 在宿主机上创建一个Linux bridge:docker0,并分配一个网段给该网桥使用。该模式下启动的容器,会分配一个该网段的IP, 并通过veth-pair接入网桥。为了能够从宿主机外部访问容器,需要在创建容器时指定-p参数,在宿主机上将某个宿主机的端口映射到容器的端口。
如:
1 | docker run --rm -itd -p 80:80 nginx |
本文来简要分析一下从宿主机外访问bridge网络模式下docker容器的数据包路径。
整体的网络架构如图所示: