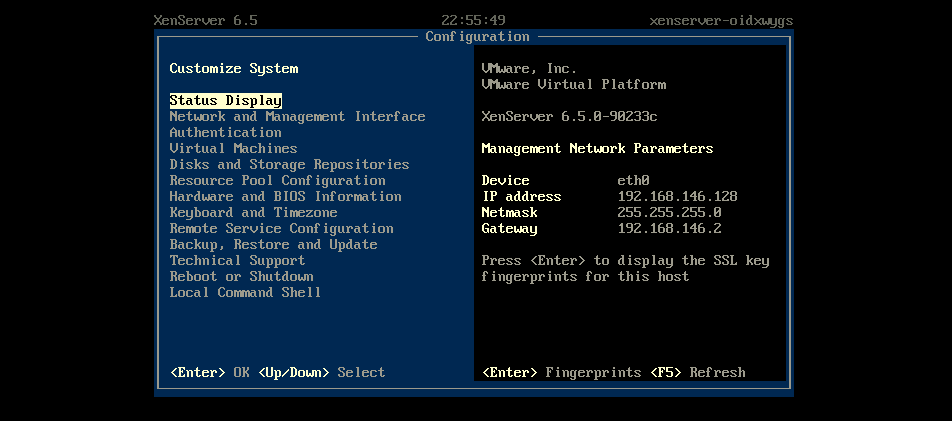
以虚拟机镜像或者自带操作系统形式交付的产品往往需要对系统进行各种各样的配置,如IP设置、DNS设置等等。为了提升用户体验,提供更简化的使用方式,往往会在console界面提供GUI/TUI的交互方式, 如XenServer的console界面:
本文介绍在CentOS7系统上增加GUI界面的方法。
Linux系统的终端输入/输出设备一般称为TTY,是TeleTypewriter的缩写, 它的历史可以参考这两篇文章:
getty是管理物理或者虚拟终端(ttys)程序的通用名称,表示get tty,用于防止非授权访问系统。当getty检测到终端连接时,它获取用户输入用户名, 然后执行login程序获取用户输入密码来进行登录校验。
从终端登录的一般过程是:
- 系统内核启动完成后,会启动
init进程,它是一号进程。 init进程会在特定的tty启动getty进程获取用户名。- 调用
exec执行login程序处理登录过程 login登录校验成功后,执行相应用户指定的shell程序