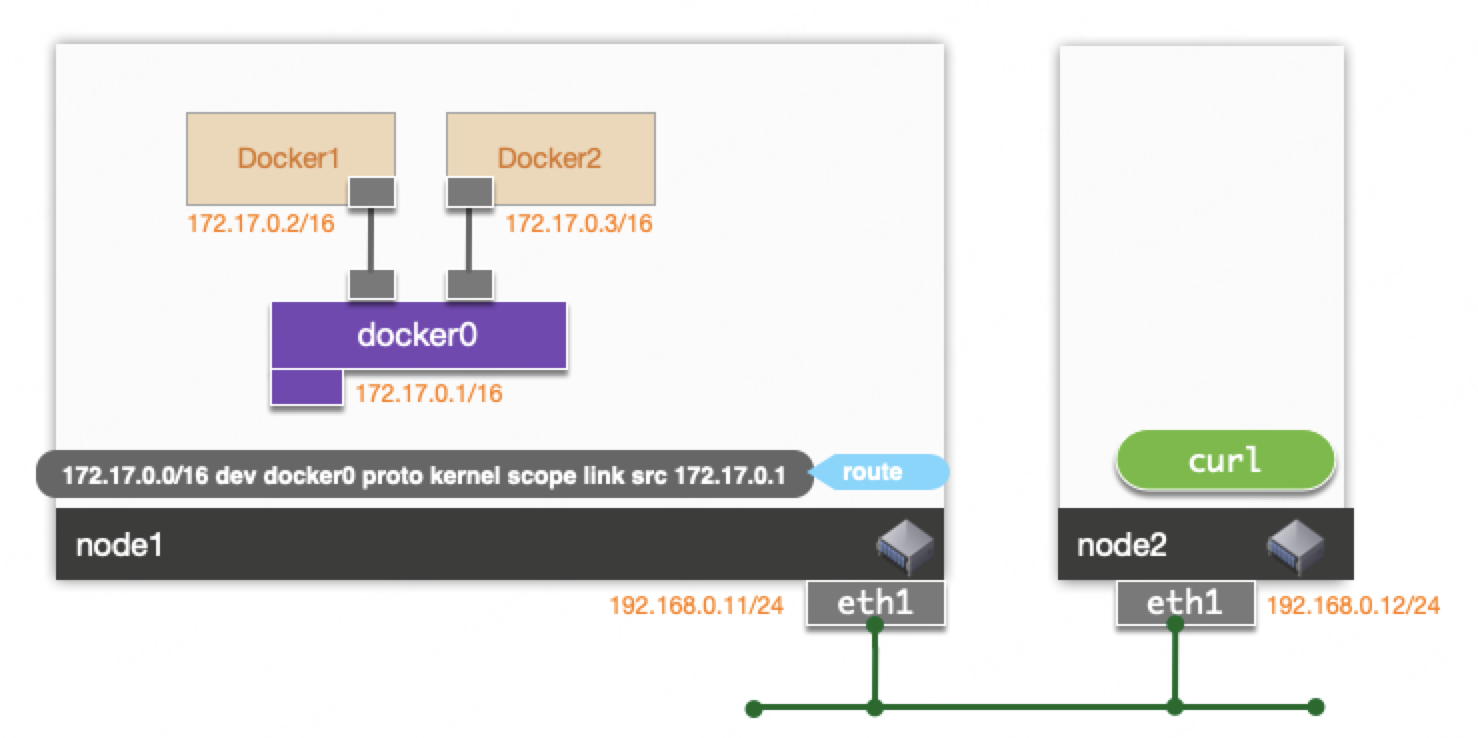
最近发现kolla安装的openstack(Ocata版本)环境中,某虚拟网络上的虚拟机对外访问异常。经过调查,发现虚拟机外发数据包经过安全组的网桥后源地址被修改为宿主机的IP。
简化的网络拓扑如图:
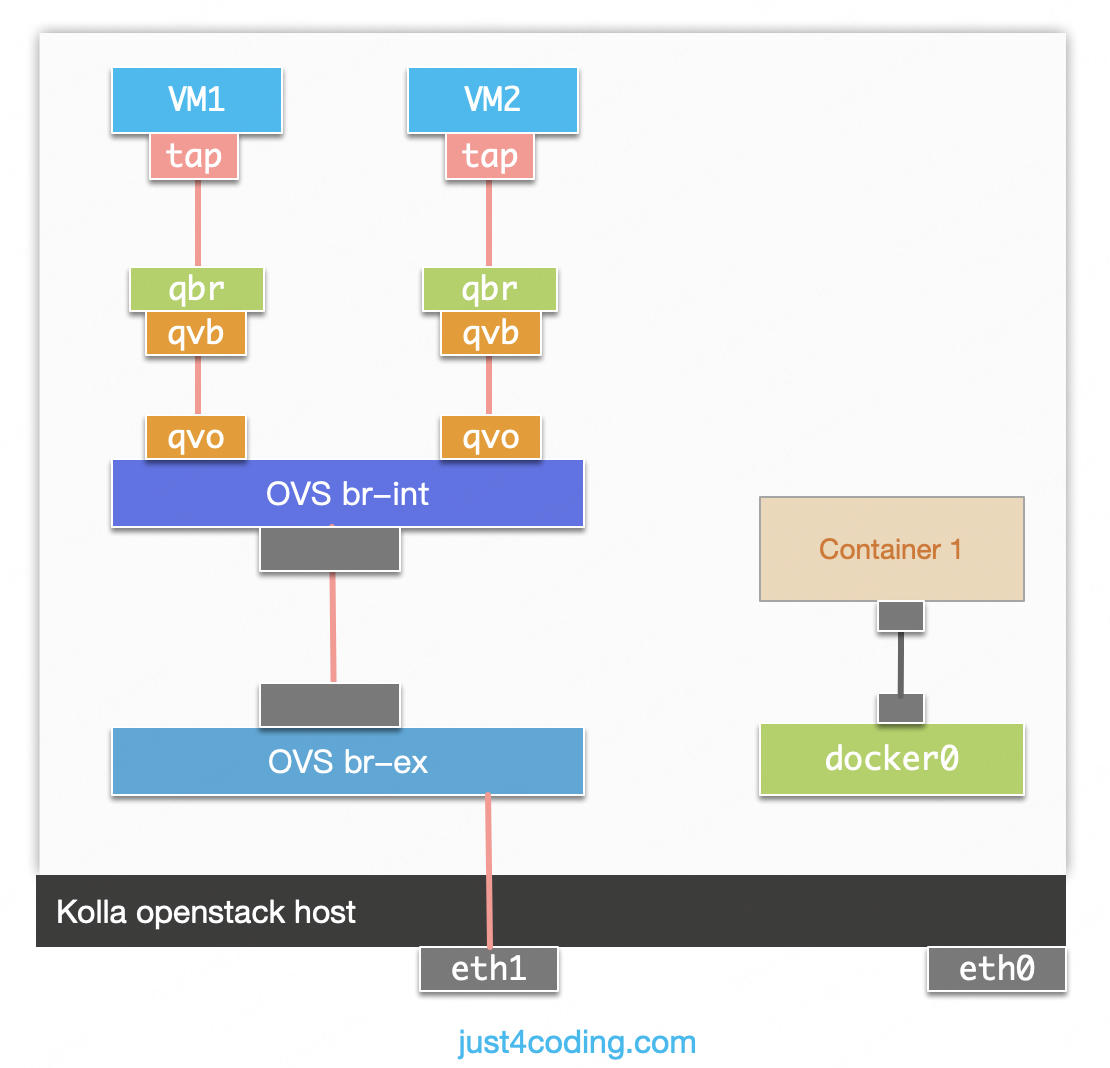
最近发现kolla安装的openstack(Ocata版本)环境中,某虚拟网络上的虚拟机对外访问异常。经过调查,发现虚拟机外发数据包经过安全组的网桥后源地址被修改为宿主机的IP。
简化的网络拓扑如图:
我们的系统使用ansible执行部署过程,然而部署的目标操作系统和CPU架构环境多种多样,存在大量适配工作。之前调研过是否有Golang开发的ansible替代物,但没有找到合适的方案。这种到处运行的场景很适合使用容器,但如果使用docker, 在不同操作系统上也需要准备不同的docker安装包,依然需要适配,因而也不是很满足。今天想到runc本身就是Golang开发的纯静态二进制,非常适合到处分发,因而尝试调研直接使用runc来做为运行时运行ansible容器。
在容器领域,OCI:Open Container Initiative制定了两个规范,镜像规范: image-spec和运行时规范:runtime-spec。镜像规范规定了镜像文件的格式,而运行时规范规定了如何根据配置运行容器。它们之间通过filesystem bundle联系在一起,镜像可以通过工具转换成filesystem bundle, 运行时根据filesystem bundle运行容器进程。
我们的主机网络防护是基于netfilter实现。最近遇到需要对访问主机上Docker容器的流量进行防护。几年前其实就处理过这个场景,时间久远忘记了,重新梳理一下记录下来。
我们的主机网络防护模块的hooknum为LOCAL_IN和POST_ROUTING, 并且hook的优先级为NF_IP_PRI_FIRST, 也就是在hooknum位置最先运行。
之前的文章<<从外部访问Docker桥接网络容器路径分析>>分析了从外部访问Docker桥接网络的网络路径。
PRE_ROUTING, FORWARD和 POST_ROUTING阶段,在PRE_ROUTING阶段会进行DNAT, 将目的IP/PORT, 修改为容器的IP/PORT。 PRE_ROUTING, FORWARD和POST_ROUTING阶段,在POST_ROUTING阶段会进行SNAT, 将源IP/PORT修改为外部宿主机的IP/PORT。从网络路径来看,在POST_ROUTING阶段数据包上的地址是容器本身的地址, 因而我们可以简单的将容器IP/PORT端口在规则中配置,就可以实现对于访问容器内部流量的防护。
我们的网络防护功能是基于netfilter框架实现,依赖于nf_conntrack模块用于跟踪网络连接。在网络连接的维度,我们需要存储一些业务相关的数据。最简单直接的方法就是将这些内容存储在nf_conn结构中。
查看nf_conn结构,发现nf_conn结构中有一个指针ext可以支持扩展:
1 | struct nf_conn { |
nf_ct_ext结构:
1 | /* Extensions: optional stuff which isn't permanently in struct. */ |
ctr和crictl都是Kubernetes环境中管理容器的命令行工具。但它们的目的和使用方法有所不同。
crictl是基于Kubernetes的CRI: Container Runtime Interface接口规范来管理容器, ctr是containerd自带的容器管理工具, 本身和Kubernetes无关。
Kubernetes使用crictl来管理任意兼容CRI接口的容器运行时。
containerd相比于docker,增加了namespace的概念,每个image和container都在各自的namespace下可见。目前kubernetes使用k8s.io作为namespace名称。
LSM: Linux Security Modules是内核中对象访问控制机制。最早的基于访问主体(subject)的身份或者所属组(User,Group,Other)的访问控制机制被称为DAC: Discretionary Access Control, 在许多安全性要求较高的场景下不能适用。于是Linux内核中实现了MAC: Mandatory Access Control机制,来表达访问主体(Subject)是否有权限对访问客体(Object)进行相应操作(Operation), 这个实现就是LSM框架。
在具体实现上,内核会在相应对象访问前进行相应操作的检测,以系统调用为例来看, 如图:
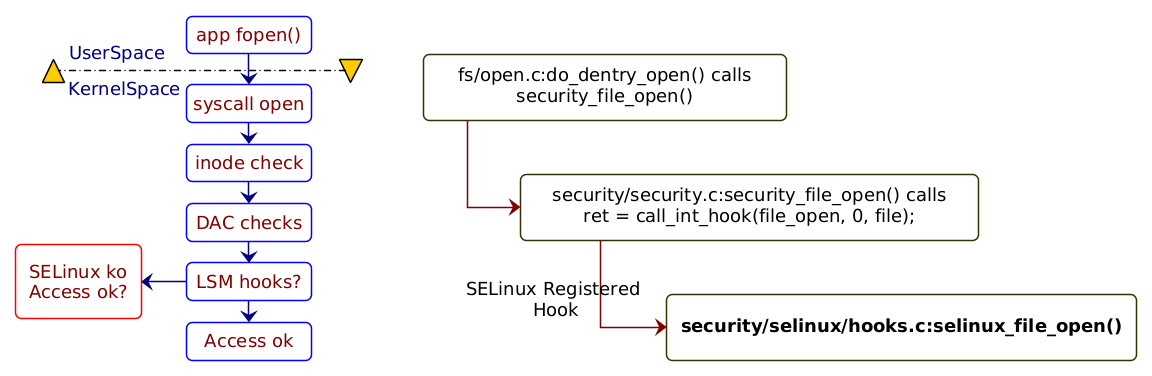
来自链接
计算机加电后,首先会执行刷在ROM/NVRAM中的系统固件代码。系统固件(BIOS/UEFI)完成自身的一系列工作(如硬件自检(POST: Power-On Self-Test)后,需要引导操作系统启动。固件可以从NVRAM中读取启动设备列表,按设备顺序尝试进行引导。
之前的文章<<CentOS7配置Console GUI/TUI程序>>介绍了在CentOS7的Console界面上配置GUI/TUI可视化程序的几种方法。尽管这些GUI程序可以简化系统的配置难度,但对于界面要求复杂的专用场景较不是很适用,比如需要支持鼠标操作等。但安装完整的一套桌面环境,对服务器的资源占用又较大,这种场景下,可以只安装X Window和openbox来支撑运行完整图形界面程序。
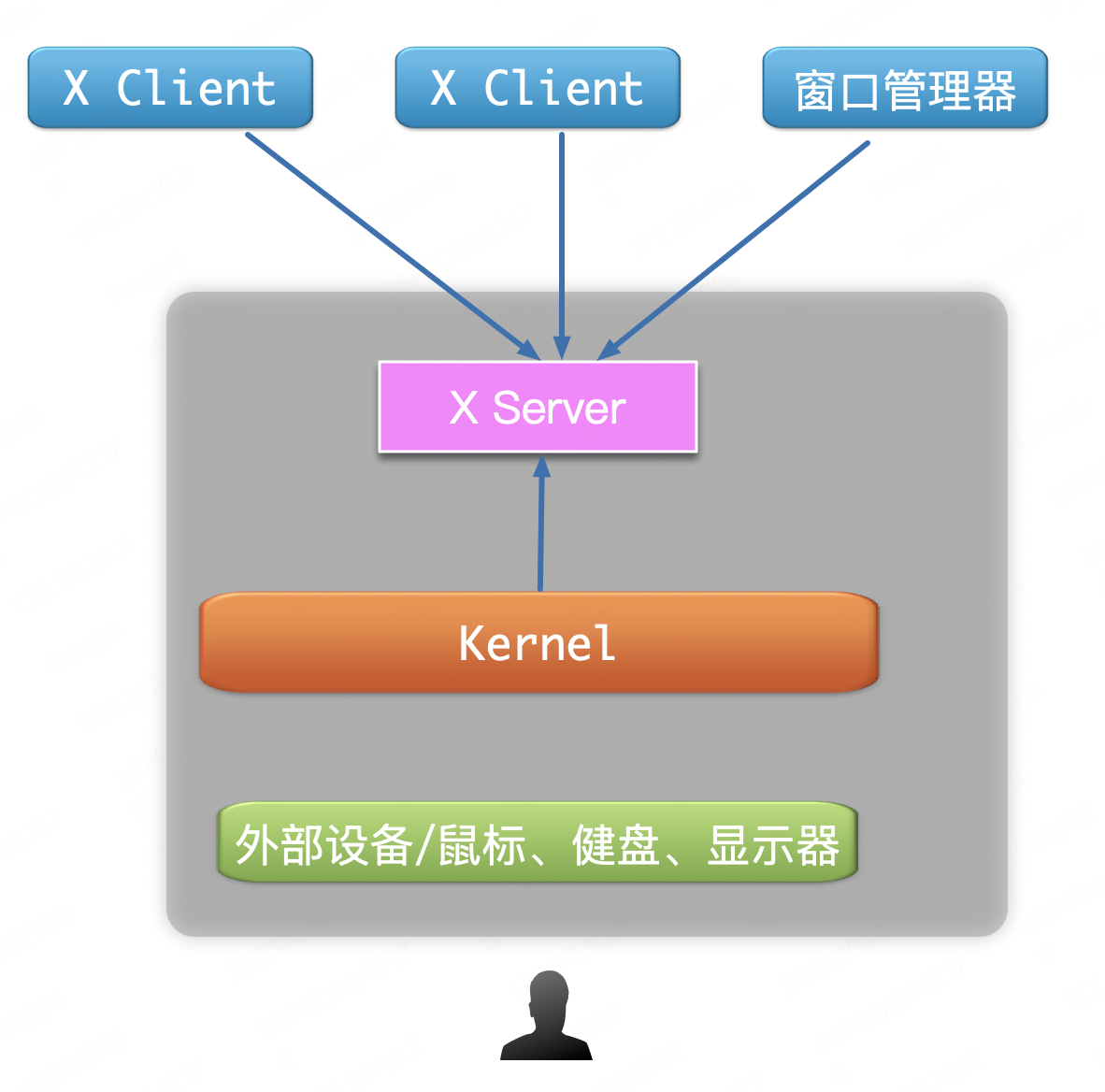
X Window被设计为Client/Server架构。Server负责图形设备和外部设备的处理来显示画图和处理外设操作,而图形界面程序作为Client只是通知Server进行相应的操作,如画线,显示字符等等。Client和Server之间不要求位于同一台计算机,它们之间可以通过网络进行协议传输。Client和Server的角色和我们日常网络访问所说的Client和Server相比。一般我们日常通过SSH登录服务器,我们所看到界面和操作外设的一端做为客户端,我们所使用的应用位于服务端。而在X Window体系下。我们看到界面和操作外设的一端是X Server, 而图形界面程序运行的一端是X Client。
对于任一X Client来说,它并不知晓其他X Client的存在,对于他们在同一X Server上如何排放,需要另一个组件来完成,这就是窗口管理器, 它也是一个X Client,只是它负责的是其他X Client的管理, 示意图如下:
近期开发的C++程序遇到一个关于locale的问题。程序在通过SSH直接登录到root用户后,运行程序会崩溃,而通过其他用户SSH登录后,再切换到root用户后,程序则运行正常。
1 | terminate called after throwing an instance of 'std::runtime_error' |
根据locale文档中的描述:
1 | std::locale::locale(const char * __s) [explicit] |
可以得知,指定的locale不存在。
Google上查到一般解决方案是设置环境变量LC_ALL=C可以解决。
Docker默认的网络模式是bridge模式, 在宿主机上创建一个Linux bridge:docker0,并分配一个网段给该网桥使用。该模式下启动的容器,会分配一个该网段的IP, 并通过veth-pair接入网桥。为了能够从宿主机外部访问容器,需要在创建容器时指定-p参数,在宿主机上将某个宿主机的端口映射到容器的端口。
如:
1 | docker run --rm -itd -p 80:80 nginx |
本文来简要分析一下从宿主机外访问bridge网络模式下docker容器的数据包路径。
整体的网络架构如图所示: