我们的程序很多业务逻辑由Lua实现,为了防止业务逻辑被曝光,需要对Lua代码进行加密。
我们有两种思路:
- 自定义字节码: Lua库可以直接调用编译后生成的Lua字节码,因而我们可以将源码编译成字节码对外提供。但是因为Lua是开源的,可以通过工具将字节码反编译回源码。我们可以自定义字节码,加大反编译的难度。
- 将Lua源码文件加密,在Lua编译字节码前,对源码文件进行解密
本文主要介绍第二种思路的实现。
我们的程序使用LuaJIT来执行Lua代码,因而以LuaJIT来说明。
我们的程序很多业务逻辑由Lua实现,为了防止业务逻辑被曝光,需要对Lua代码进行加密。
我们有两种思路:
本文主要介绍第二种思路的实现。
我们的程序使用LuaJIT来执行Lua代码,因而以LuaJIT来说明。
Citrix提供了DDK(Driver Development Kit)来支持在XenServer中要构建自定义的内核模块或硬件驱动。DDK是一个OVA格式的虚拟机镜像,包含了内核头文件和编译器等开发工具。
下面介绍使用DDK构建内核模块的步骤。
首先从官方下载相应版本DDK,这里选择6.5:
http://downloadns.citrix.com.edgesuite.net/10106/XenServer-6.5.0-DDK.iso
将下载的ISO文件上传到XenServer宿主机上
挂载ISO
1 | mkdir /mnt/tmp |
Lua通过标准库实现了核心之外的功能,如math库,I/O库等。本文来分析math标准库的实现, 代码位于lmathlib.c。
math库提供了一组标准的数学函数,如绝对值函数, 三角函数,随机数函数等。调用方式为:
1 | a = math.abs(-1) |
标准库由C语言函数实现,提供给Lua程序使用。Lua程序与C函数通过虚拟栈交互。Lua将参数压入栈中,C函数从栈中获取参数,并将结果压入栈中,C函数返回入栈的结果数量。C函数无需在压入结果前清空栈,Lua会在函数执行完成后从栈中获取结果并自动清空结果下的内容。
Lua调用的C函数的格式是固定的,定义在lua.h中:
1 | typedef int (*lua_CFunction) (lua_State *L); |
默认情况下,Lua源码编译后会生成三个文件:
Lua 是一种解释型语言,执行方式如图:
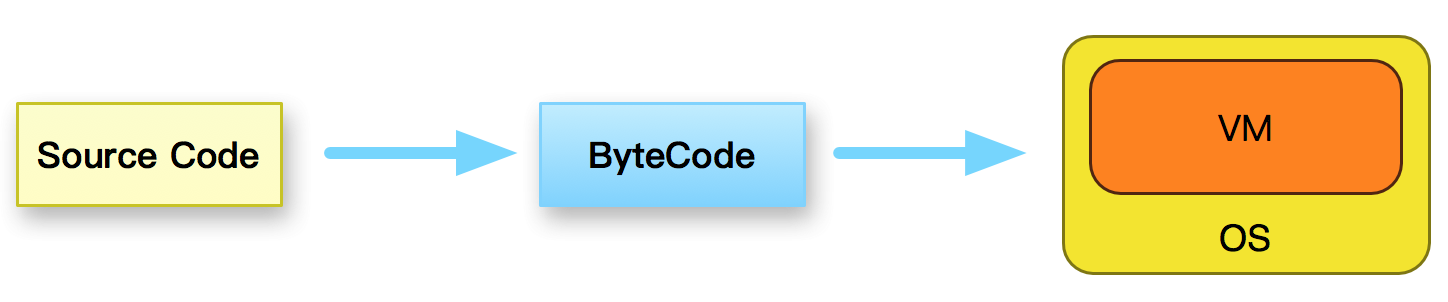
首先将Lua源码编译成Lua字节码,然后由虚拟机来执行Lua字节码。
Thrift(https://thrift.apache.org/)是一个轻量级、语言无关的RPC框架。它定义了一套简单直观的IDL(Interface Definition Language)用于描述服务接口规范。 通过代码生成引擎将IDL描述的接口规范生成各种目标语言(如C++
,JAVA等)的源码文件。应用开发者基于这些源码构建服务端和客户端。通过这种方式,Thrift屏蔽了不同语言间的数据序列化/反序列化、数据传输、网络通信等与业务逻辑不相关的部分,使开发者只需关心业务逻辑实现。
twemproxy(https://github.com/twitter/twemproxy)是Twitter开源的Redis和Memcached代理程序,它可以将多个后端server组织成一个ServerPool, 基于请求的Key从Pool中选取一个server实例进行操作,从而实现分片存储。
twemproxy采用事件驱动处理网络数据收发。程序启动后会单独创建一个线程来处理stats请求,而主线程进入事件循环处理访问所有ServerPool的Redis或Memcached请求。
我们的NGINX的IP封禁功能基于Redis实现。当只支持单IP封禁时,直接以IP作为KEY,调用”GET”命令,根据Value判断是否需要封禁该IP。若要支持网段封禁,需要取出所有的CIDR段,然后判断IP是否在CIDR范围内。随着CIDR越来越多,从Redis中取出的数据则越来越多,性能消耗越来越大。为了减少数据传输量,则可以将判断逻辑改由Redis来完成。
Redis本身支持Lua脚本的执行,可以由Lua来实现相应逻辑。不过Lua语言本身不支持位运算(5.2之后支持),需要第三方库支持。所以,我们直接通过修改Redis代码扩展Redis命令来实现该功能。
在LVS的FULLNAT转发模式下, LVS对数据包同时做SNAT和DNAT,将数据包的源IP、源端口更换为LVS本地的IP和端口,将数据包的目的IP和目的端口修改为RS的IP和端口,从而不再依赖特定网络拓朴转发数据包。
这种方式存在一个问题: RealServer中接收到数据包中源IP和源端口为LVS机器的IP和端口,这样应用层程序获取到的TCP连接的客户端地址为LVS的IP地址,很多依赖客户端地址的功能就不能正常工作了。
为了解决这问题,FULLNAT模式在转发包的时候,在TCP包中添加一个OPTION,来传递客户端的真实地址。RealServer中通过内核模块toa令应用层程序获取真实的客户端地址。
Varnish使用状态机机制处理请求,在各个状态中,用户通过使用Varnish自己实现的VCL(Varnish Configuration Language)定制处理逻辑。
比如,Varnish接收并解析完请求就进入vcl_recv状态。在这个阶段,我们可以使用VCL来决定是否要服务该请求,怎么服务,以及使用哪个Backend来服务等。
VCL实现了状态的流程控制,请求信息的读取和修改等,但很多业务层面需要的逻辑没办法由VCL简单完成。比如,对某些信息进行BASE64编码等等。由于Varnish支持外部模块,用户可以使用C语言开发自己的模块,由VCL来调用这些模块来完成这些处理。但每种功能都由C模块来开发成本较大。
Lua是一种优秀的脚本语言,可以非常轻松地嵌入C语言中,而Lua语言本身有大量的库来实现各种各样的功能。因而我开发了VMOD_LUA这个Varnish模块,使用它来执行Lua脚本,由Lua代码来定制各种处理逻辑。
ngx_http_limit_conn_module模块用来限制某个KEY的并发连接数。它的实现与ngx_http_limit_req_module模块类似,整体逻辑和实现更为简单。LimitConn模块也将某个KEY的信息存储在共享内存RBTREE中的节点中, 但不需要QUEUE结构。LimitConn模块只需要在节点中记录当前的连接数信息:
1 | typedef struct { |