之前的文章<<VMware vSphere虚拟网络防护>>介绍了VMware vSphere的网络基础知识和南北向网络安全防护的思路。南北向网络防护是在网络边界进行安全隔离和流量过滤。那么怎样对网络内部的东西向流量如何进行安全防护呢?VMware NSX提供了东西向安全防护的能力。不过NSX的License价格很贵,很多企业并没有购买意愿。本文介绍在非NSX环境中只依赖vSphere提供的能力将流量引至虚拟安全设备实现东西向网络安全防护的思路。
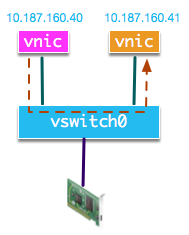
我们当前一台ESXi上的环境如图:
之前的文章<<VMware vSphere虚拟网络防护>>介绍了VMware vSphere的网络基础知识和南北向网络安全防护的思路。南北向网络防护是在网络边界进行安全隔离和流量过滤。那么怎样对网络内部的东西向流量如何进行安全防护呢?VMware NSX提供了东西向安全防护的能力。不过NSX的License价格很贵,很多企业并没有购买意愿。本文介绍在非NSX环境中只依赖vSphere提供的能力将流量引至虚拟安全设备实现东西向网络安全防护的思路。
我们当前一台ESXi上的环境如图:
云计算环境的一个典型属性是多租户共享物理资源。其中每个租户可以构建自己专属的虚拟逻辑网络,而每个逻辑网络都需要由唯一的标识符来标识。不同的逻辑网络默认情况下相互隔离。传统上,网络工程师一般使用VLAN来隔离不同二层网络,但VLAN的标识符命名空间只有12位,只能提供4096个标识符,这无法满足大型云计算环境的需求。另外,使用VLAN隔离虚拟逻辑网络,往往需要对底层物理网络设备进行手动配置,这无法满足云计算环境的自动化需求。为了解决VLAN在网络虚拟化环境中应用存在的种种问题,Cisco,VMware等厂商提出了新的网络协议VXLAN来隔离虚拟逻辑网络。
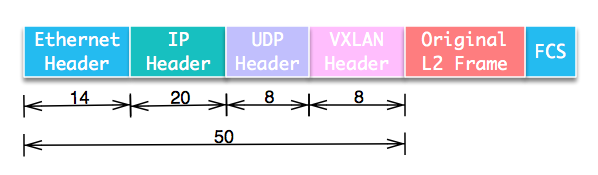
VXLAN的全称为Virtual eXtensible LAN,从名称看,它的目标就是扩展VLAN协议。802.1Q的VLAN TAG只占12位,只能提供4096个网络标识符。而在VXLAN中,标识符扩展到24位,能提供16777216个逻辑网络标识符,VXLAN的标识符称为VNI(VXLAN Network Identifier)。另外,VLAN只能应用在一个二层网络中,而VXLAN通过将原始二层以太网帧封装在IP协议包中,在IP基础网络之上构建overlay的逻辑大二层网络。
我们来看具体协议包结构。VXLAN将二层数据帧封装在UDP数据包中,构建隧道在不同节点间通信。包结构如图:
随着数据中心虚拟化和云计算发展,虚拟网络的安全防护需求越来越多。本文通过实例介绍VMware vSphere虚拟网络的安全防护。
首先介绍VMware vSphere虚拟网络的基础知识。
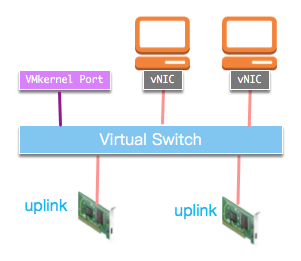
ESXi主机使用虚拟交换机来路由虚拟网络内部流量以及虚拟网络和物理网络之间的网络流量。vSphere有三种虚拟交换机:
vSS工作在单一ESXi主机中,适用于小规模环境,需要在每个ESXi主机上单独配置。vDS和Nexus 1000v具备更多高级网络特性, 但需要额外License。本文介绍在vSS环境下的虚拟网络防护。
vSS有三种类型的端口:
vSS通过端口组(Port Group)将vNIC端口分组,针对端口组,可以设置不同的VLAN ID,安全参数、流量整形参数等。在创建虚拟机时需要指定虚拟网络接口属的端口组。
vSphere虚拟网络的架构示意图如下:
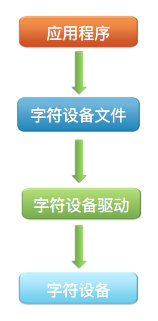
字符设备是Linux内核中按字节顺序读写的设备。字符设备需要与/dev目录下的设备文件关联,应用程序通过访问设备文件与字符设备完成双向数据通信。结构如图所示:
内核使用设备号来标识设备,设备号分为主设备号和次设备号。主设备号用于标识特定的驱动程序,表示设备类别,次设备号被驱动程序用于识别操作的具体设备。
Linux内核支持动态加载或卸载模块。这种机制使得不用重新编译内核就可以方便地扩展内核功能,也减小了内核镜像的大小。一般情况下,Linux设备驱动都以模块形式来实现,需要时再加载。
内核模块的扩展名为.ko, 一般位于/lib/modules/<kernel_version>/kernel目录下。
本文通过一个”hello world”级别的内核模块,来展示内核模块如何开发。
NFQUEUE是iptables的一种规则目标, 它用于将网络数据包从内核传给用户态进程, 由用户态进程来裁决如何处理该数据包,并将裁决结果返回内核。传输通道为以数字标识的队列。队列由固定长度的链表实现,链表元素为数据包及元数据(kernel skb结构)。在内核中,Netfilter框架尝试将符合规则的数据包放入队列中。若队列已满,则丢弃该数据包。因此,若用户态进程处理过慢,则会严重影响网络性能。内核与用户态进程之间基于NFNETLINK通信,数据包需要在内核态与用户态之间进行拷贝,因而这种机制的性能比较差。
下面,以实例来说明NFQUEUE机制。
下面的命令会将发送给本机80端口的TCP数据包送往队列80:
1 | iptables -A INPUT -p tcp --dport 80 -j NFQUEUE —-queue-num 80 |
之前文章<<ARP代理实例研究>>提到: 在默认配置下,只要ARP请求中的目标IP配置在本机,无论其是否配置在收到ARP请求数据包的接口上,Linux收包接口都会以身MAC地址发送ARP响应。若是不希望接口响应所有本机IP,可以通过修改arp_ignore参数来调整。
那么如果机器上多个网卡连接在同一交换机,这样多个网卡会收到相同的ARP请求。若多个网卡都回复,则客户端应该收到多个ARP响应。这种情况下,Linux是如何处理的呢?
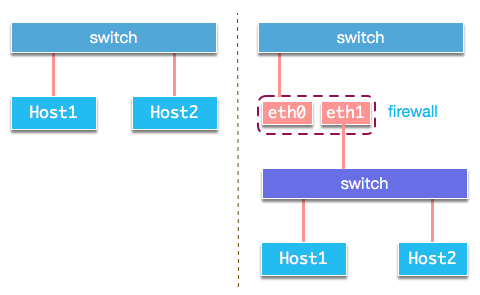
ARP代理指网络接口对要查询的IP不属于本机的ARP请求以自身的MAC地址给予ARP响应。从而发送到该目的IP的数据包被捕获到代理设备,代理设备再从其他网络接口将数据包转发至目的IP。
ARP代理的一个典型应用场景是防火墙部署。通过将防火墙部署在被保护主机前面,开启ARP代理功能,可以不修改被保护主机的网络配置,将流量引导至防火墙对流量进行过滤。部署前后结构如图:
在默认配置下,只要ARP请求中的目标IP配置在本机,无论其是否配置在收到数据包的接口上,Linux收包接口都会以身MAC地址发送ARP响应。若是不希望接口响应所有本机IP,可以通过修改arp_ignore参数来调整,可以参考之前的文章<<ARP协议介绍>>。
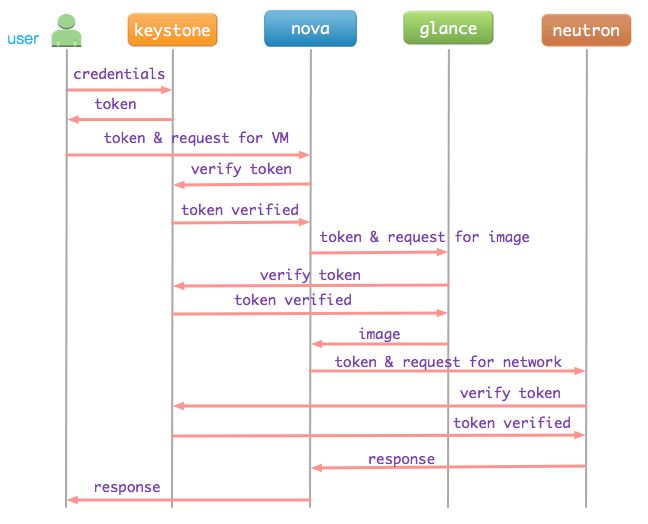
OpenStack由一系列REST API服务组成,如NOVA提供计算服务,GLANCE提供镜像服务,NEUTRON提供网络服务。Keystone是这些服务之一,它为其他服务提供统一的身份认证和授权服务。它的工作模式如图:
Web应用程序的处理逻辑可以概括为:
其中,接收HTTP请求和发送HTTP响应,主要是解析HTTP请求,构造HTTP协议响应,这些与业务无关,不需要每次开发Web应用程序都重新实现,因而已经存在许多独立可以直接使用的组件,这种组件称为WebServer,而业务逻辑处理部分则称为Application。WebServer和Application之间通过约定好的协议或规范进行通信。
WSGI(Web Server Gateway Interface)是Python社区提出的WebServer与Application之间通信的规范, 当前版本为v1.0.1, 定义在PEP 3333(https://www.python.org/dev/peps/pep-3333/)。