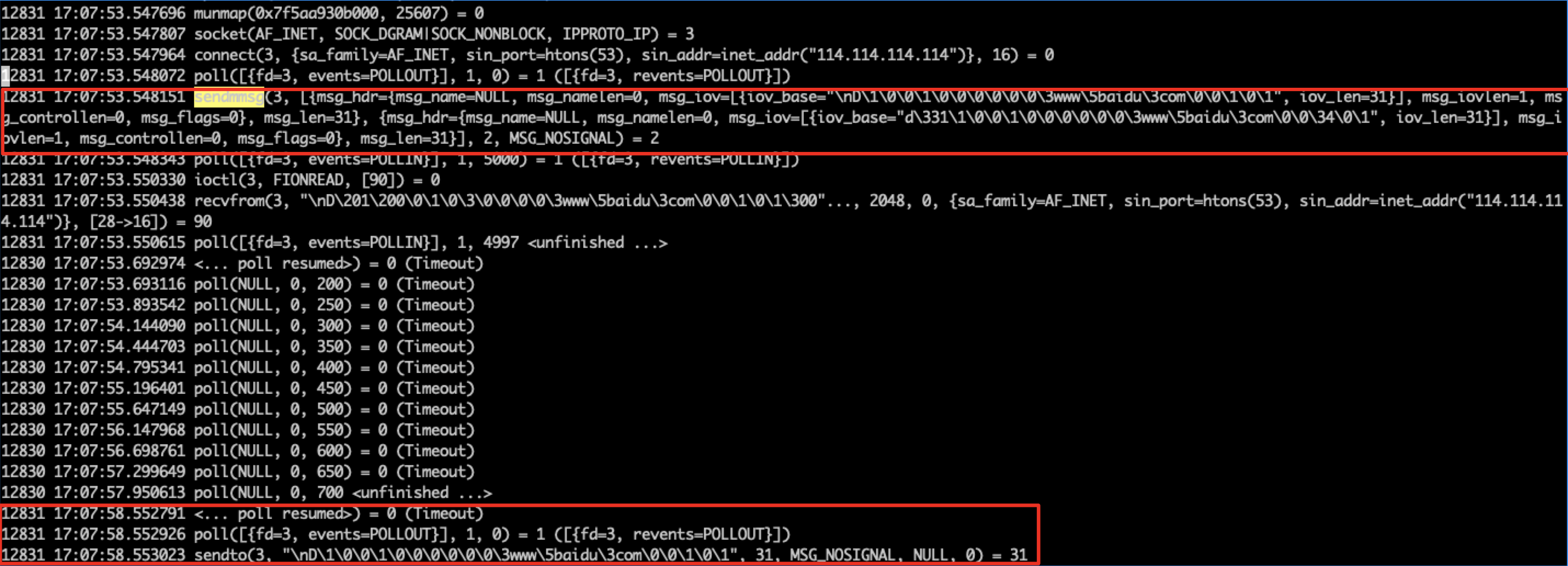
weave公司的文章Racy conntrack and DNS lookup timeouts介绍了在较旧版本内核的conntrack模块中存在的BUG会导致UDP丢包。其中一种场景是当不同的线程通过相同的socket发送UDP数据包时,存在竞争条件两个数据包都会各自创建一个conntrack条目,但两个条目所包含的tuple信息是一致的,这种情况会导致丢包。
/* Confirm a connection given skb; places it in hash table */ int __nf_conntrack_confirm(struct sk_buff *skb) { unsignedint hash, repl_hash; structnf_conntrack_tuple_hash *h; structnf_conn *ct; structnf_conn_help *help; structnf_conn_tstamp *tstamp; structhlist_nulls_node *n; enumip_conntrack_infoctinfo; structnet *net; u16 zone;
ct = nf_ct_get(skb, &ctinfo); net = nf_ct_net(ct);
/* ipt_REJECT uses nf_conntrack_attach to attach related ICMP/TCP RST packets in other direction. Actual packet which created connection will be IP_CT_NEW or for an expected connection, IP_CT_RELATED. */ if (CTINFO2DIR(ctinfo) != IP_CT_DIR_ORIGINAL) return NF_ACCEPT;
zone = nf_ct_zone(ct); /* reuse the hash saved before */ hash = *(unsignedlong *)&ct->tuplehash[IP_CT_DIR_REPLY].hnnode.pprev; hash = hash_bucket(hash, net); repl_hash = hash_conntrack(net, zone, &ct->tuplehash[IP_CT_DIR_REPLY].tuple);
/* We're not in hash table, and we refuse to set up related connections for unconfirmed conns. But packet copies and REJECT will give spurious warnings here. */ /* NF_CT_ASSERT(atomic_read(&ct->ct_general.use) == 1); */
/* No external references means no one else could have confirmed us. */ NF_CT_ASSERT(!nf_ct_is_confirmed(ct)); pr_debug("Confirming conntrack %p\n", ct);
spin_lock_bh(&nf_conntrack_lock);
/* We have to check the DYING flag inside the lock to prevent a race against nf_ct_get_next_corpse() possibly called from user context, else we insert an already 'dead' hash, blocking further use of that particular connection -JM */
if (unlikely(nf_ct_is_dying(ct))) { spin_unlock_bh(&nf_conntrack_lock); return NF_ACCEPT; }
/* See if there's one in the list already, including reverse: NAT could have grabbed it without realizing, since we're not in the hash. If there is, we lost race. */ hlist_nulls_for_each_entry(h, n, &net->ct.hash[hash], hnnode) if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple, &h->tuple) && zone == nf_ct_zone(nf_ct_tuplehash_to_ctrack(h))) goto out; hlist_nulls_for_each_entry(h, n, &net->ct.hash[repl_hash], hnnode) if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_REPLY].tuple, &h->tuple) && zone == nf_ct_zone(nf_ct_tuplehash_to_ctrack(h))) goto out;
/* Remove from unconfirmed list */ hlist_nulls_del_rcu(&ct->tuplehash[IP_CT_DIR_ORIGINAL].hnnode);
/* Timer relative to confirmation time, not original setting time, otherwise we'd get timer wrap in weird delay cases. */ ct->timeout.expires += jiffies; add_timer(&ct->timeout); atomic_inc(&ct->ct_general.use); ct->status |= IPS_CONFIRMED;
/* set conntrack timestamp, if enabled. */ tstamp = nf_conn_tstamp_find(ct); if (tstamp) { if (skb->tstamp.tv64 == 0) __net_timestamp(skb);
tstamp->start = ktime_to_ns(skb->tstamp); } /* Since the lookup is lockless, hash insertion must be done after * starting the timer and setting the CONFIRMED bit. The RCU barriers * guarantee that no other CPU can find the conntrack before the above * stores are visible. */ __nf_conntrack_hash_insert(ct, hash, repl_hash); NF_CT_STAT_INC(net, insert); spin_unlock_bh(&nf_conntrack_lock);
help = nfct_help(ct); if (help && help->helper) nf_conntrack_event_cache(IPCT_HELPER, ct);
single-request-reopen (since glibc 2.9) The resolver uses the same socket for the A and AAAA requests. Some hardware mistakenly sends back only one reply. When that happens the client system will sit and wait for the second reply. Turning this option on changes this behavior so that if two requests from the same port are not handled cor‐ rectly it will close the socket and open a new one before sending the second request.