在应用开发中,应用程序往往需要跟据特定策略的决策结果来判断后续执行何种操作。比如,权限校验就是策略决策的一种典型场景,它需要判断哪些用户对哪些资源能够执行哪些操作。这些策略可能随着时间需要不断的动态更新。当前策略决策的逻辑往往硬编码实现在软件的业务逻辑中,当需要更新策略规则集时,还需要修改应用代码、重新部署应用,非常不灵活。同时,不同的应用服务也都需要重复实现类似的功能,因而策略决策逻辑非常适合做为独立的模块从业务逻辑中抽离出来。
Open Policy Agent,官方简称OPA, 为这类策略决策需求提供了一个统一的框架与服务。它将策略决策从软件业务逻辑中解耦剥离,将策略定义、决策过程抽象为通用模型,实现为一个通用策略引擎,可适用于广泛的业务场景,比如:
- 判断某用户可以访问哪些资源
- 允许哪些子网对外访问
- 工作负载应该部署在哪个集群
- 二进制物料可以从哪些仓库下载
- 容器能执行哪些操作系统功能
- 系统能在什么时间被访问
需要注意的是,OPA本身是将策略决策和策略施行解耦,OPA负责相应策略规则的评估,即决策过程,业务应用服务需要根据相应的策略评估结果执行后续操作,策略的施行是业务强相关,仍旧由业务应用来实现。
OPA的整体逻辑结构如下图:
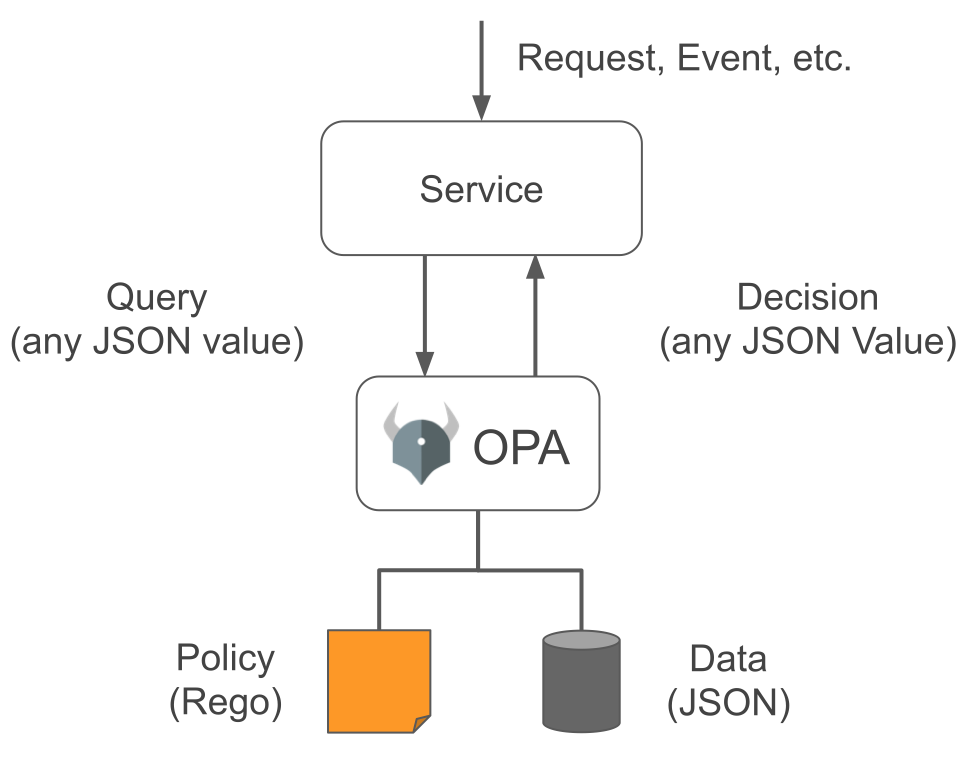
OPA的策略决策过程涉及三个部分:
- 数据(Data): 数据是OPA评估策略时所需的外部信息。比如,在实现用户级粒度的简单访问控制时,OPA需要知道所有允许访问的用户列表。它是JSON格式文档。
- 查询输入(Query): 它触发策略评估过程,并为其提供参数,它也是JSON格式文档。
- 策略(Policy): 策略指定了计算逻辑,它根据数据和查询输入来执行计算逻辑产生策略的评估结果。
这三部分内容被提交给OPA策略引擎,策略引擎解析策略中所包含的规则,并基于数据与查询输入的参数做出策略决策,并将决策返回给应用服务。所返回的决策内容也是JSON格式文档。
OPA自定义了一种声明性语言Rego来定义策略。具体语法参考:
官方文档对于为何使用Rego,列出了如下理由:
- 容易阅读和编写
- 支持嵌套的数据结构
- Rego是声明式语言,策略编写专注在策略查询结果而不是策略如何执行,相较于命令式语言会更加简洁。
- OPA可以优化查询以提高性能
这些优势在大多数场景下有其价值。然而,对于非常复杂的策略表达,我个人还是更倾向于集成Lua这类轻量级的命令式语言,实现相对复杂的逻辑计算过程,同时可以依赖其完整生态极大的扩充策略表达的灵活性。当然,不恰当的策略实现对OPA运行时的影响风险也会更大。
业务应用可以通过sidecar容器、独立服务或者依赖库(针对Golang应用)几种方式集成OPA。
OPA以daemon方式运行支持HTTP RestAPI, 业务应用可以调用相关API完成集成,详细文档可以参考:
我们以一个简单的访问控制独立服务来示例说明。
首先创建数据文件acl.json:
1 | { |
在这个数据文件中,我们给alice分配read和write两个权限,给bob只分配read权限。
接着编辑输入数据文件input1.json:
1 | { |
编辑策略文件acl.rego:
1 | package myapi.policy |
在这个策略文件中,我们定义了两个规则allow和whocan,allow规则首先从数据中查找输入参数user的权限列表,然后判断是否具备输入参数所要求的权限。whocan规则返回具备所查询的权限的所有用户组成的数组。从这示例也可以看出OPA的查询结果不只可以返回简单的true/false, 可以返回结构化的JSON文档,应用场景非常灵活。
接下来以独立服务启动OPA:
1 | ./opa run -s |
OPA服务启动后监听8181端口。
我们将数据文件加载到OPA:
1 | curl -X PUT http://localhost:8181/v1/data/demo/acl --data-binary @acl.json |
接着加载策略:
1 | curl -X PUT http://localhost:8181/v1/policies/demo --data-binary @acl.rego |
注意URI:/v1/policies/demo中的demo是该策略的ID,只用于该策略的管理,如更新、删除。策略决策时所使用的规则由Rego文件中的package语句所指定,这里对应对RestAPI的URI path为: /v1/data/demo/policy/.
我们以input1.json文件来查询策略规则allow,判断alice是否具备write权限:
1 | [root@localhost open-police-agent]# curl -s -X POST http://localhost:8181/v1/data/demo/policy/allow --data-binary @input1.json |jq |
再定义一个输入文件input2.json:
1 | { |
我们来查询规则allow来判断bob是否具备write权限:
1 | [root@localhost open-police-agent]# curl -s -X POST http://localhost:8181/v1/data/demo/policy/allow --data-binary @input2.json |jq |
接下来,我们来查询具备read权限的所有用户:
1 | [root@localhost open-police-agent]# curl -s -X POST http://localhost:8181/v1/data/demo/policy/whocan --data-binary '{"input":{"access":"read"}}' |jq |
返回结果为JSON数组。
目前已经有相当多的开源项目可以集成OPA,参考:
本文简要的介绍了OpenPolicyAgent的应用场景,更深入的理解可以参考官方文档和以下链接: