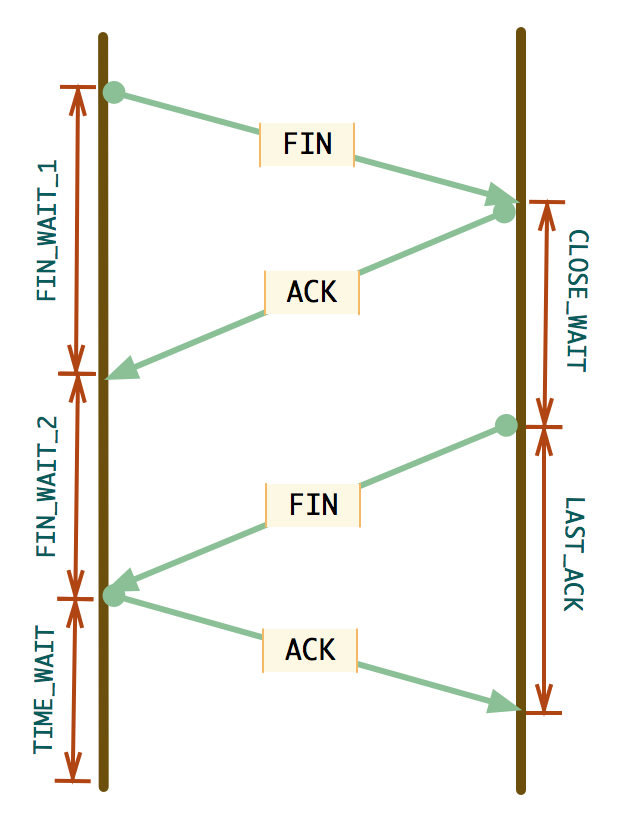
TIME_WAIT是排查TCP连接问题经常遇到的一种TCP状态。首先我们来看TIME_WAIT状态是如何产生的。TCP关闭连接的状态变化图如下:
可以看到,主动关闭连接的一端在发送最后一个ACK后进入TIME_WAIT状态。TIME_WAIT状态会持续2倍的MSL(Maximum Segment Lifetime),MSL是指一个TCP分段在网络上存在的最大时间,因而TIME_WAIT状态也被称为2MSL状态。
TIME_WAIT状态的作用主要有两个:
可靠的关闭连接。假设主动关闭连接的一端发送的最后一个ACK分段在网络中丢包或被延迟了,被动关闭的一端因收不到ACK,会重新发送FIN包。这时如果没有TIME_WAIT状态直接处于CLOSED状态,就会直接响应RST而不会响应ACK。极端情况下,ACK到达对端需要一个MSL,对端重发的FIN到达需要一个MSL,当2个MSL之后仍未收到重传的FIN,则认为对端已经收到了ACK。
防止上一次连接中的分段延迟到达后影响新连接。TCP连接由五元组(协议,源IP,源端口,目的IP,目的端口, 因而协议固定是TCP,也可以说是四元组)唯一标识。假设没有TIME_WAIT状态,一个连接关闭后,可能使用相同的五元组的新连接被建立,这时若原连接上的TCP分段因为网络延时刚刚到达,且它的序列号刚好在新连接的接收窗口,则会令新连接接收的数据混乱。尽管每次建立连接使用的序列号都是随机产生的,但是序列号的长度只有32位,在高速网络上可能很快出现序列号循环。TIME_WAIT状态持续2MSL后,原连接的数据包都已经在网络上消失,不会再干扰新连接。
现在我们知道TIME_WAIT是TCP的正常状态。然而,当机器上存在大量TIME_WAIT状态的socket时, 不主动连接(客户端)和被动连接(服务器端)的场景下对服务器有不同的影响。
首先来看主动连接场景。
主动连接端会占用本地端口,TIME_WAIT状态socket占用的本地端口过多的话,会导致本地端口不足,TCP连接不能成功建立。
可以调整参数net.ipv4.ip_local_port_range来增加本地端口的选择范围,但这样效果有限。还可以启用net.ipv4.tcp_tw_reuse参数来重用TIME_WAIT状态的socket。
内核文档对于该参数的描述如下:
1 2 3 4 5 tcp_tw_reuse - BOOLEAN Allow to reuse TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. Default value is 0. It should not be changed without advice/request of technical experts.
下面来看该参数具体如何实现。
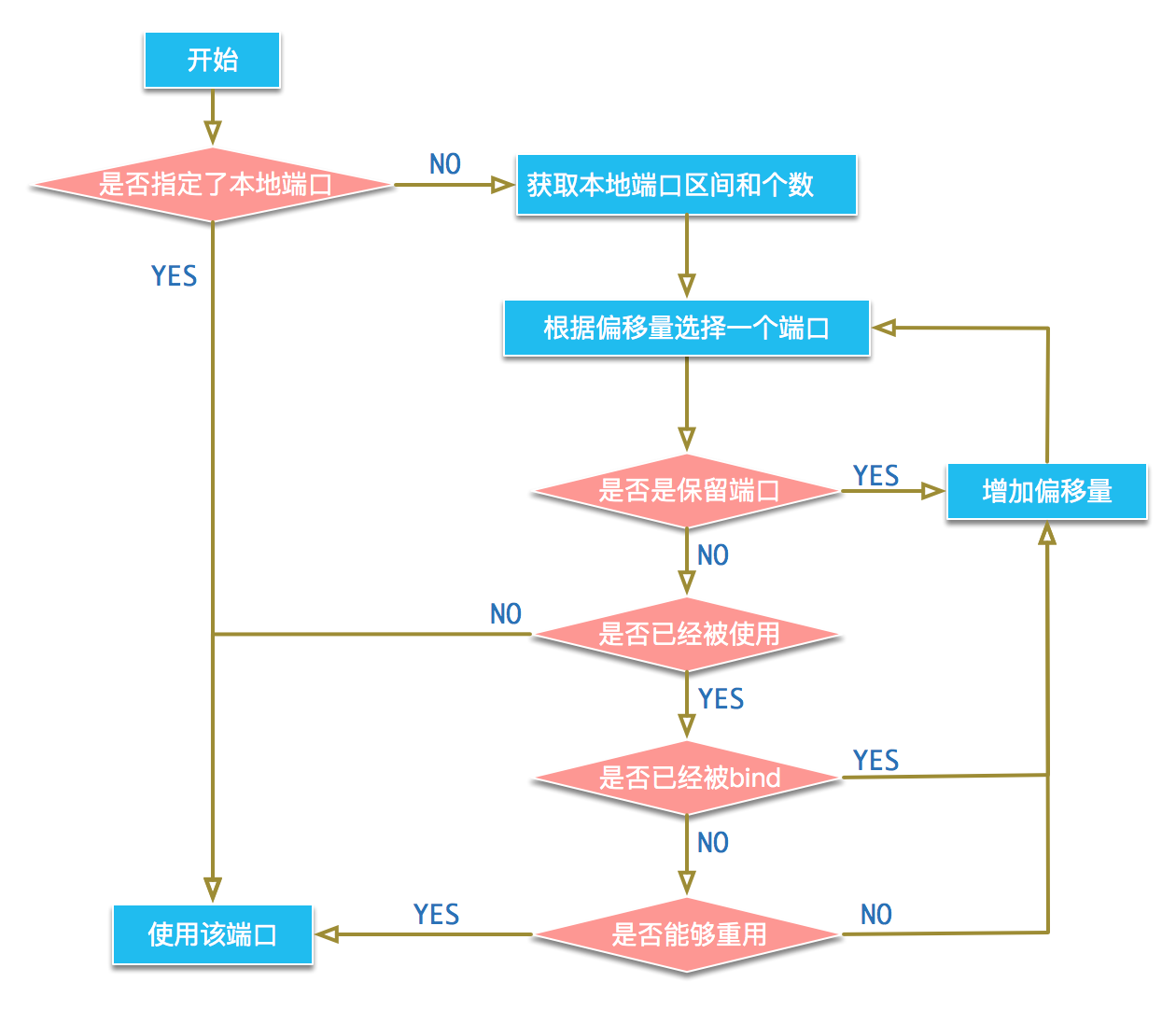
本地端口的选取过程如图:
net/ipv4/inet_hashtables.c中的函数__inet_check_established用来检查已经在使用的端口是否能够重用,对于TIME_WAIT状态的socket会调用tcp_twsk_unique来判断。
tcp_twsk_unique的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int tcp_twsk_unique (struct sock *sk, struct sock *sktw, void *twp) { const struct tcp_timewait_sock *tcptw = struct tcp_sock *tp = if (tcptw->tw_ts_recent_stamp && (twp == NULL || (sysctl_tcp_tw_reuse && get_seconds() - tcptw->tw_ts_recent_stamp > 1 ))) { tp->write_seq = tcptw->tw_snd_nxt + 65535 + 2 ; if (tp->write_seq == 0 ) tp->write_seq = 1 ; tp->rx_opt.ts_recent = tcptw->tw_ts_recent; tp->rx_opt.ts_recent_stamp = tcptw->tw_ts_recent_stamp; sock_hold(sktw); return 1 ; } return 0 ; }
只有当net.ipv4.tcp_timestamps选项启用时,tcptw->tw_ts_recent_stamp才会为真, net.ipv4.tcp_tw_reuse启用时,sysctl_tcp_tw_reuse才会为真。从代码可以看到,当tcp_timestamps和tcp_tw_reuse两个选项开启时,若该socket距离上次收到数据包已经超过1秒,则可以重用该端口。
Linux的TCP实现将TIME_WAIT状态持续时间硬编码在了源码中, 设置为60秒,在include/net/tcp.h:
1 2 #define TCP_TIMEWAIT_LEN (60*HZ)
这个值并不能通过sysctl来修改,如果需要修改该时间值,则需要修改内核代码重新编译。
下面来验证tcp_tw_reuse的效果:NGINX并且不主动关闭连接,客户端使用curl来访问服务器并主动关闭连接来产生TIME_WAIT状态的socket。curl连接成功时返回值为0,失败时返回值为7。我们以此判断连接是否成功。
为了使实验简单,将本地端口范围修改为只有三个端口可用:
1 sysctl -w net.ipv4.ip_local_port_range="32768 32770"
确保tcp_tw_reuse选项为关闭状态:
1 2 [root@localhost ~]# sysctl -a |grep reuse net.ipv4.tcp_tw_reuse = 0
编写实验脚本,脚本逻辑为先执行3次curl访问服务器,占满全部本地端口,2秒之后再执行一次curl访问。脚本内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 for i in `seq 1 3`do echo $i date curl http://10.95.48.11/ -o /dev/null -s echo "RETURN: " $? ss -atn |grep TIME done sleep 2echo "4" date curl http://10.95.48.11/ -o /dev/null -s echo "RETURN: " $?
在客户端执行脚本, 可以看到第4次请求会失败:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [root@localhost ~]# sh t.sh 1 Thu Nov 9 15:51:57 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 2 Thu Nov 9 15:51:57 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32770 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 3 Thu Nov 9 15:51:57 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32768 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32770 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 4 Thu Nov 9 15:51:59 CST 2017 RETURN: 7
接着我们将tcp_tw_reuse和tcp_timestamps选项启用:
1 2 3 4 [root@localhost ~]# sysctl -w net.ipv4.tcp_tw_reuse=1 net.ipv4.tcp_tw_reuse = 1 [root@localhost ~]# sysctl -w net.ipv4.tcp_timestamps=1 net.ipv4.tcp_timestamps = 1
再次执行shell脚本, 第4次请求会成功返回0:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [root@localhost ~]# sh t.sh 1 Thu Nov 9 15:50:10 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32768 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32770 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 2 Thu Nov 9 15:50:10 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32768 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32770 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 3 Thu Nov 9 15:50:10 CST 2017 RETURN: 0 TIME-WAIT 0 0 192.168.10.131:32768 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32770 10.95.48.11:80 TIME-WAIT 0 0 192.168.10.131:32769 10.95.48.11:80 4 Thu Nov 9 15:50:12 CST 2017 RETURN: 0
开启tcp_tw_reuse选项可以使主动连接的一端在主动关闭的场景下每秒能建立6万多个连接。如果每秒要建立更多的连接呢?可以使用tcp_tw_recycle选项。
内核文档对于该参数的描述如下:
1 2 3 4 tcp_tw_recycle - BOOLEAN Enable fast recycling TIME-WAIT sockets. Default value is 0. It should not be changed without advice/request of technical experts.
相较于tcp_tw_reuse只在需要时重用TIME_WAIT状态socket, tcp_tw_recycle处理更激进,它会快速回收TIME_WAIT状态的socket。
内核代码中有定时器来调用tcp_time_wait函数来处理TIME_WAIT状态的socket,函数源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 void tcp_time_wait (struct sock *sk, int state, int timeo) { struct inet_timewait_sock *tw =NULL ; const struct inet_connection_sock *icsk = const struct tcp_sock *tp = int recycle_ok = 0 ; if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp) recycle_ok = icsk->icsk_af_ops->remember_stamp(sk); if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets) tw = inet_twsk_alloc(sk, state); if (tw != NULL ) { struct tcp_timewait_sock *tcptw =struct sock *)tw); const int rto = (icsk->icsk_rto << 2 ) - (icsk->icsk_rto >> 1 ); tw->tw_rcv_wscale = tp->rx_opt.rcv_wscale; tcptw->tw_rcv_nxt = tp->rcv_nxt; tcptw->tw_snd_nxt = tp->snd_nxt; tcptw->tw_rcv_wnd = tcp_receive_window(tp); tcptw->tw_ts_recent = tp->rx_opt.ts_recent; tcptw->tw_ts_recent_stamp = tp->rx_opt.ts_recent_stamp; #if defined(CONFIG_IPV6) || defined(CONFIG_IPV6_MODULE) if (tw->tw_family == PF_INET6) { struct ipv6_pinfo *np = struct inet6_timewait_sock *tw6 ; tw->tw_ipv6_offset = inet6_tw_offset(sk->sk_prot); tw6 = inet6_twsk((struct sock *)tw); ipv6_addr_copy(&tw6->tw_v6_daddr, &np->daddr); ipv6_addr_copy(&tw6->tw_v6_rcv_saddr, &np->rcv_saddr); tw->tw_ipv6only = np->ipv6only; } #endif #ifdef CONFIG_TCP_MD5SIG do { struct tcp_md5sig_key *key ; memset (tcptw->tw_md5_key, 0 , sizeof (tcptw->tw_md5_key)); tcptw->tw_md5_keylen = 0 ; key = tp->af_specific->md5_lookup(sk, sk); if (key != NULL ) { memcpy (&tcptw->tw_md5_key, key->key, key->keylen); tcptw->tw_md5_keylen = key->keylen; if (tcp_alloc_md5sig_pool(sk) == NULL ) BUG(); } } while (0 ); #endif __inet_twsk_hashdance(tw, sk, &tcp_hashinfo); if (timeo < rto) timeo = rto; if (recycle_ok) { tw->tw_timeout = rto; } else { tw->tw_timeout = TCP_TIMEWAIT_LEN; if (state == TCP_TIME_WAIT) timeo = TCP_TIMEWAIT_LEN; } inet_twsk_schedule(tw, &tcp_death_row, timeo, TCP_TIMEWAIT_LEN); inet_twsk_put(tw); } else { LIMIT_NETDEBUG(KERN_INFO "TCP: time wait bucket table overflow\n" ); } tcp_update_metrics(sk); tcp_done(sk); }
从代码上可以看到只有当tcp_timestamps和tcp_tw_recycle都开启时,才会快速回收。而根据代码:
1 const int rto = (icsk->icsk_rto << 2 ) - (icsk->icsk_rto >> 1 );
可以看到回收的超时时间为3.5 * RTO, RTO是由TCP分段中timestamp选项计算得到的,一般场景下这个时间在几百毫秒左右。
从上面的tcp_time_wait源码也可以看出, 当TIME_WAIT状态的socket数量超过tcp_max_tw_buckets选项指定的数量值时,会直接关闭socket,进入CLOSED状态,内核日志中会报错:
1 TCP: time wait bucket table overflow
的错误。若把tcp_max_tw_buckets选项设置为0,则可以直接跳过TIME_WAIT状态。
然而,tcp_tw_recycle选项在NAT环境使用有一些隐患,下面来分析一下。
协议栈收到syn包时会调用到函数tcp_v4_conn_request, 该函数部分源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 if (tmp_opt.saw_tstamp && tcp_death_row.sysctl_tw_recycle && (dst = inet_csk_route_req(sk, req)) != NULL && (peer = rt_get_peer((struct rtable *)dst)) != NULL && peer->v4daddr == saddr) { if (get_seconds() < peer->tcp_ts_stamp + TCP_PAWS_MSL && (s32)(peer->tcp_ts - req->ts_recent) > TCP_PAWS_WINDOW) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_PAWSPASSIVEREJECTED); goto drop_and_release; } }
其中TCP_PAWS_MSL和TCP_PAWS_WINDOW分别为60和1:
1 2 3 4 5 6 7 8 9 10 #define TCP_PAWS_MSL 60 #define TCP_PAWS_WINDOW 1
从代码上我们可以看到,当开启tcp_timestamps和tcp_tw_recycle选项时,60秒内来自同一源IP主机的TCP分段的时间戳必须递增,否则该分段会被直接丢弃。
假如多个客户端从NAT环境访问服务器,服务器端看到的对端IP是一样的,但是TCP分段的时间戳会不一样。当时间戳较大的客户端连接成功后的60秒内,时间戳较小的客户端再次连接服务器,syn包会被服务器直接丢弃,导致连接失败。
我们来通过实验验证。首先基于libvirt构造NAT环境。n1.xml:
1 2 3 4 5 6 7 8 9 10 <network > <name > n1</name > <bridge name ="n1" /> <forward mode ="nat" /> <ip address ="192.168.10.1" netmask ="255.255.255.0" > <dhcp > <range start ="192.168.10.2" end ="192.168.10.254" /> </dhcp > </ip > </network >
启用实验网络:
1 2 virsh net-define n1.xml virsh net-start n1
再启动两台虚拟机做为客户端,将其接口设置在实验网络中:
1 2 3 <interface type ="network" > <source network ="n1" /> </interface >
虚拟机启动后,在两台机器上抓包确认出两台机器TCP时间戳的大小。
将服务器端的NGINX配置keepalive_timeout设为0,令服务器端主动关闭连接,重新加载NGINX配置生效。
将服务器的tcp_timestamps和tcp_tw_recycle选项启动:
1 2 3 4 [root@bogon conf]# sysctl -w net.ipv4.tcp_tw_recycle=1 net.ipv4.tcp_tw_recycle = 1 [root@bogon conf]# sysctl -w net.ipv4.tcp_timestamps=1 net.ipv4.tcp_timestamps = 1
首先在时间戳较小的客户端上执行curl, 连接成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~]# curl http://10.95.48.11 -o /dev/null -s -v * About to connect() to 10.95.48.11 port 80 (#0) * Trying 10.95.48.11... connected * Connected to 10.95.48.11 (10.95.48.11) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.21 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2 > Host: 10.95.48.11 > Accept: */* > < HTTP/1.1 200 OK < Server: openresty/1.11.2.5 < Date: Thu, 09 Nov 2017 11:07:55 GMT < Content-Type: text/html < Content-Length: 562 < Last-Modified: Thu, 21 Sep 2017 20:02:30 GMT < Connection: close < ETag: "59c41ad6-232" < Accept-Ranges: bytes < { [data not shown] * Closing connection #0
接着在时间戳较大的客户端上执行curl,连接也成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~]# curl http://10.95.48.11 -o /dev/null -s -v * About to connect() to 10.95.48.11 port 80 (#0) * Trying 10.95.48.11... connected * Connected to 10.95.48.11 (10.95.48.11) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.21 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2 > Host: 10.95.48.11 > Accept: */* > < HTTP/1.1 200 OK < Server: openresty/1.11.2.5 < Date: Thu, 09 Nov 2017 11:08:07 GMT < Content-Type: text/html < Content-Length: 562 < Last-Modified: Thu, 21 Sep 2017 20:02:30 GMT < Connection: close < ETag: "59c41ad6-232" < Accept-Ranges: bytes < { [data not shown] * Closing connection #0
而这时立即再次从时间戳较小机器上执行,可以发现连接失败了:
1 2 3 4 5 [root@localhost ~]# curl http://10.95.48.11 -o /dev/null -s -v * About to connect() to 10.95.48.11 port 80 (#0) * Trying 10.95.48.11... Connection timed out * couldn't connect to host * Closing connection #0
一分钟之后重试, 则连接成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [root@localhost ~]# curl http://10.95.48.11 -o /dev/null -s -v * About to connect() to 10.95.48.11 port 80 (#0) * Trying 10.95.48.11... connected * Connected to 10.95.48.11 (10.95.48.11) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.21 Basic ECC zlib/1.2.3 libidn/1.18 libssh2/1.4.2 > Host: 10.95.48.11 > Accept: */* > < HTTP/1.1 200 OK < Server: openresty/1.11.2.5 < Date: Thu, 09 Nov 2017 11:11:51 GMT < Content-Type: text/html < Content-Length: 562 < Last-Modified: Thu, 21 Sep 2017 20:02:30 GMT < Connection: close < ETag: "59c41ad6-232" < Accept-Ranges: bytes < { [data not shown] * Closing connection #0
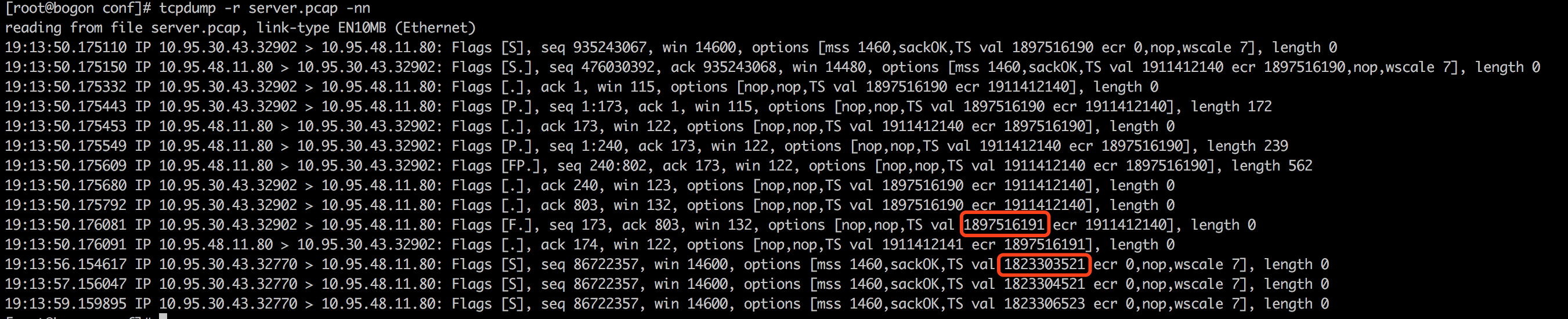
我们从服务器端的抓包结果可以看到失败请求的TCP时间戳小于之前的时间戳:
在被动连接的情况下,若产生了大量的TIME_WAIT状态,并没有特别大的性能影响,只是会多消耗一些内存与端口链表查找的CPU资源。
了解了这些关于TIME_WAIT相关的知识背景就可以根据应用场景来灵活调整相应的参数设置了。