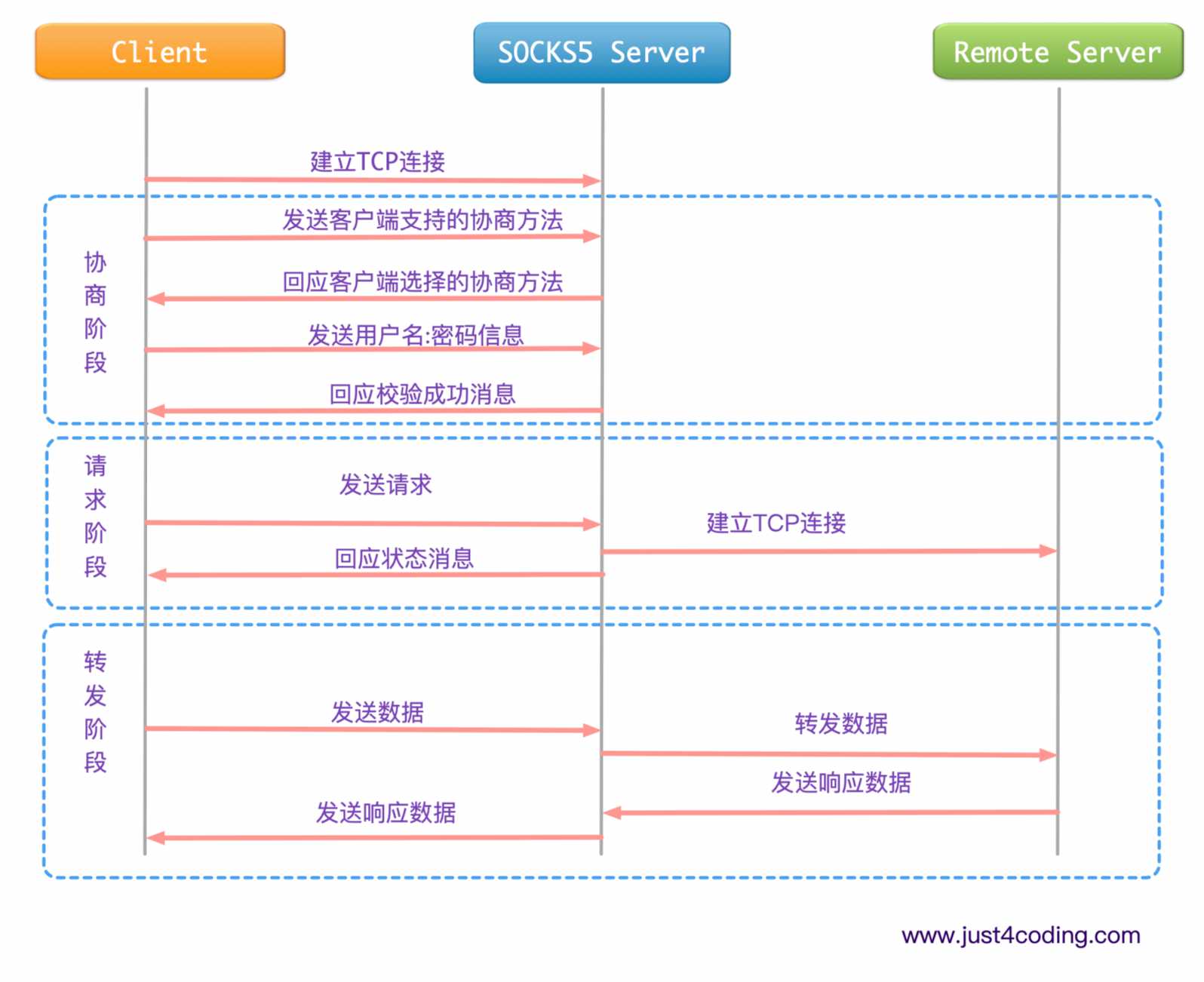
之前的文章<<使用eBPF和BCC调查创建文件的进程>>介绍了基于BCC来实现eBPF程序。BCC实现了对eBPF的封装,用户态部分提供Python API, 内核态部分使用的eBPF程序还是通过C语言来实现。运行时BCC会把eBPF的C程序编译成字节码、加载到内核执行,最后再通过用户空间的前端程序获取执行状态。
可以在BCC的BPF调用中,指定参数debug=4, 我们可以看到BCC的执行过程, 如:
1 | from bcc import BPF |
eBPF编程的门槛还是比较高的,在当前还是快速发展的情况,API也还不稳定,对程序员的C语言、编译过程和内核等知识都有比较高的要求。BCC把这些都封装起来给用户提供了一个更为简单的使用框架。但本身也存在的一些问题,比如:
- 每次执行时都需要重新编译
- 执行程序的机器都需要安装内核头文件
eBPF: extended Berkeley Packet Filter是对BPF(现在称为cBPF: classic BPF)的扩展, 现在尽管还叫做BPF, 但应用场景已经远远超过了它的名称的范畴。它的应用范围的扩大主要得益于这几方面:
- 内核中
BPF字节码虚拟机扩展为一个通用的执行引擎 - 执行可节码的安全校验
JIT支持,可以直接将字节码指令转成内核可执行的原生指令运行
这样在安全性、可编程性和性能方面的提升都使得eBPF在包过滤以外的其他领域获取巨大的应用空间。